

Move faster with new feature flag capabilities in AWS
I always get excited about things that allow you to bring new ideas to production faster. And it seems we are in luck! During the yearly AWS re:Invent conference that took place in Las Vegas, AWS launched several services that help you do just that!
Business around us is changing more and more rapidly. Year by year, the State of Devops research confirms that high performing companies excel in adapting to those changes by optimizing their ability to experiment, deliver quickly and gather feedback directly. You need to try many ideas and quickly find out which are successful and which are not. That ability to make many small changes reduces risk and increases the ability to innovate.
The new AWS services around feature flags enable organizations to achieve these goals. I will explain these briefly and show you how you can leverage them.

Moving fast
So what ingredients do you need to go fast? First, you have to optimize your organization and teams so they can come up with diverse ideas. Make sure you enable them to try those out and get feedback quickly without having to go through committees to get approval.
Second, on the engineering side, you need to learn to do everything in small steps. Integrate all your changes with the rest of your team often, at least daily. This way of working is called trunk-based development. The key here is never letting go of high quality and keeping your software in a constant state of being able to deploy it to production. To achieve that, you need a (continuous) delivery pipeline that automates all the steps needed to get from commit to deploy. As excellently explained by Dave Farley, the key responsibility of that pipeline is not to ensure that the software is 100% correct – that is not realistic. Instead, the pipeline needs to do all that it can to figure out if something might be broken or misbehaving. That means you’ll need at least a solid automated test suite that provides you with confidence that on the functional side everything works. Next to that, you can add validations to your pipeline for things like performance, code quality, and any other aspects that are important for your application.
If you do everything in small steps, does that mean you cannot have big innovations? No, of course it doesn’t. Big innovations never happen in one go. They are the combination of smaller increments, even the failed ones that you learned from. Like Edison’s light bulb, which was the result of thousands of failed experiments.
Feedback, as early as possible
A common trick is to separate the deployment of changes from the release of a feature. By using feature flags, you can include the new code you are writing without the feature showing up or being active. With all the code being deployed continuously, the act of “releasing” a feature simply becomes toggling the feature flag.
This way of working helps greatly in catching mistakes or wrong assumptions in your ideas early, while it is still easy to try another approach. It is much better to discover that your idea does not work after a few hours than finding out weeks later, when you’ve already invested a lot of time. You also make it much easier to experiment with new features much earlier in their development, maybe just exposing them to a few interested beta users and receive feedback before you make the feature generally available.

Enter feature flags
I always like keeping things simple. The easiest way to implement feature flags is to just add some booleans and ‘if statements’ in your code and allow these to be toggled between the different environments you have. For example, showing the new feature you are working on in your staging environment, but hiding and deactivating it in production. To be honest, in many cases, a simple mechanism like this is more than sufficient.
Do realize there is a tradeoff when using feature flags. Having these branches in your code means you add complexity and you make your application less predictable. In many cases the benefits greatly outweigh the downside, as long as you keep it under control. Don’t let hundreds of feature flags linger around. Be responsible, be a good craftsman and keep your codebase clean. Once a feature is released, clean up all traces of the flag. That way you minimize complexity and keep your codebase lean and mean and easy to change. After all, you want to keep doing more experiments and keep delivering value in a sustainable way.
Depending on how long your build pipeline takes, having to change booleans in code may mean that it takes a while to toggle a feature in production. This may be ok in some cases, but when it turns out that a feature doesn’t play nice on production yet, you want to toggle it off again quickly. What if you could toggle it in real-time and let someone else handle part of the complexity around feature flags?
Launch 1: AWS AppConfig – Feature Flags
AWS AppConfig has been around since 2019 and allows you to roll out configuration changes to your applications in real-time, without having to deploy code or take your application out of service. It can validate and then roll out configuration changes gradually while monitoring your application and rolling back changes in case of errors, minimizing impact to users.
Recently AWS launched AWS AppConfig Feature Flags, which builds on AppConfig and makes it easier to roll out new configurations of your feature toggles. You can now setup and toggle feature flags directly from the AWS Console. Versions of your feature flags configuration are tracked and as with config changes, you can manage and monitor the gradual deployment to your environments.
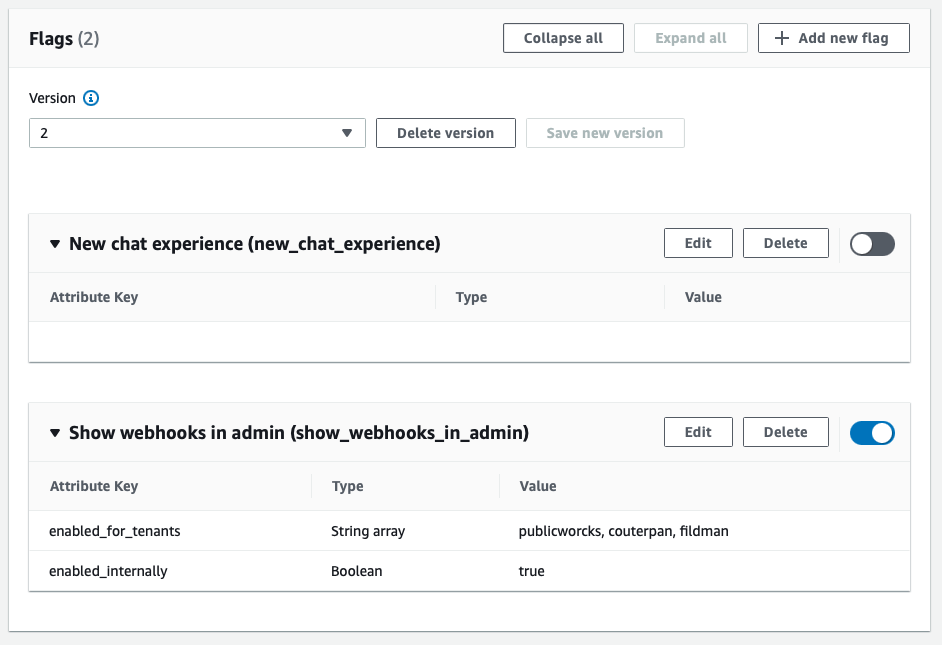
As feature flags are just booleans, there is no validation around them. You can also add custom attributes to flags. An example of what I would use these for is creating flags that are only enabled for specific beta tenants. For these attributes you can set up some simple validation rules in the UI. That may not be as powerful as writing a validation lambda as you can do for normal AppConfig validation, but it sure is a lot simpler and probably sufficient. And don’t forget, less handcrafted code means you reduce risk.

Apart from feature flags, you can also use this feature to toggle operational aspects of your application quickly. For example, in case of an incident you can temporarily switch off non-critical functionality or behavior to reduce load and keep the essentials of your service working, allowing your team to focus on resolving the incident.
That all sounds fantastic, but it does mean that releases of features are no longer tracked in your central git history, instead they are changed through the AWS Console. Luckily, the Console does track versions of your configurations and shows you the history of feature flags and configuration deployments that have been done to each of your environments. So, it may not be in one place anymore, but you can still audit when features went live or were rolled back. Just be aware that you are making this tradeoff.
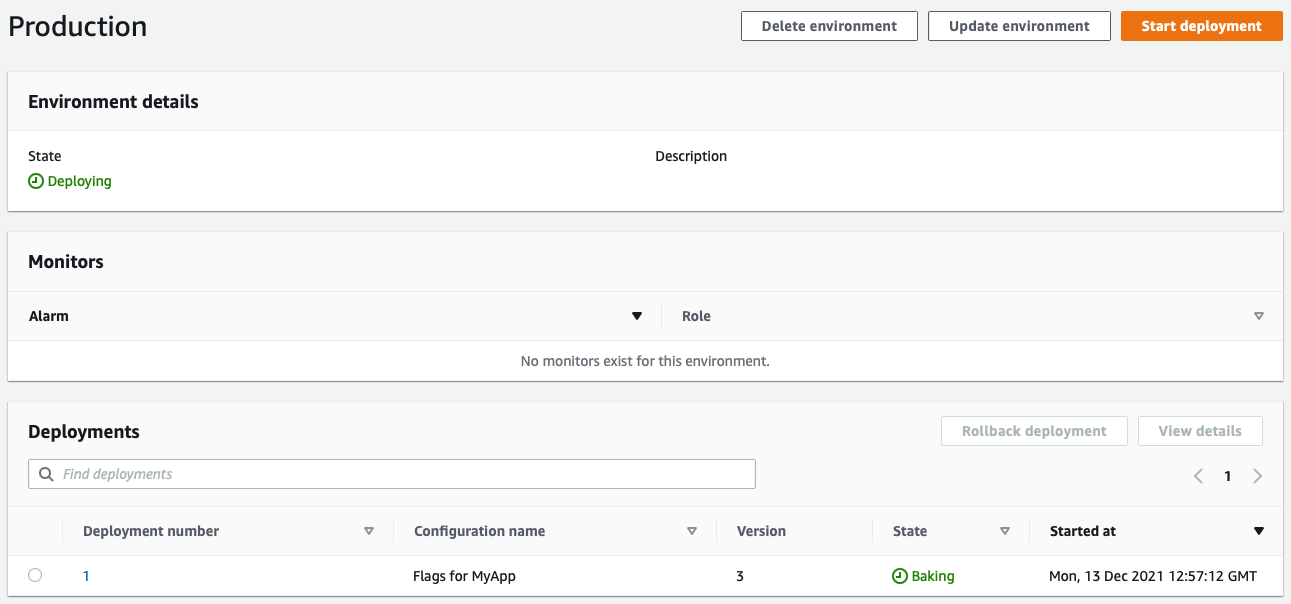
Launch 2: AWS CloudWatch – Evidently
Where AppConfig Feature Flags is geared towards simplifying the technicality of managing feature flags and their deployment, Evidently is all about connecting the data you collect for experiments and A/B tests around feature roll outs that you do with smaller sets of users before making the feature generally available.
Evidently allows you to set up multiple variants of a feature and test these variants on different subsets of users at the same time. Once you have set up and are running such an experiment, Evidently also helps in statistically analyzing which variant is performing better, based on data collected during the experiment, giving you confidence in making the right choices.
In today’s fast paced world, you have to continuously reinvent your business to remain relevant. To do so you have to innovate and Evidently really helps you with tools to apply that mindset of running experiments and basing your decisions on the data that you gather.

Launch 3: Amazon CloudWatch RUM (Real User Monitoring)
Now obviously, to make a service like Evidently work well, you need to collect the right data. Data that helps you prove the effectiveness and desired behavior of the features you build. To help with this, AWS launched RUM, another service under the CloudWatch umbrella.
CloudWatch is all about monitoring, but so far that was mostly oriented towards raw infrastructure and backend metrics of apps running inside AWS. RUM enhances that with capabilities to monitor web application performance, aimed at user experience. You inject some JavaScript into your web application frontend which then allows you to anonymously collect page load and layout performance metrics, JavaScript errors and client-side experienced HTTP errors.

Where traditional CloudWatch metrics are somewhat raw, RUM feels more like Google Analytics, giving you out-of-the-box dashboards that provide visibility into your application’s reliability, performance, and end user satisfaction. The service performs analysis on the collected data and breaks it down so you can gain insights about which areas of your application’s user experience can be improved.
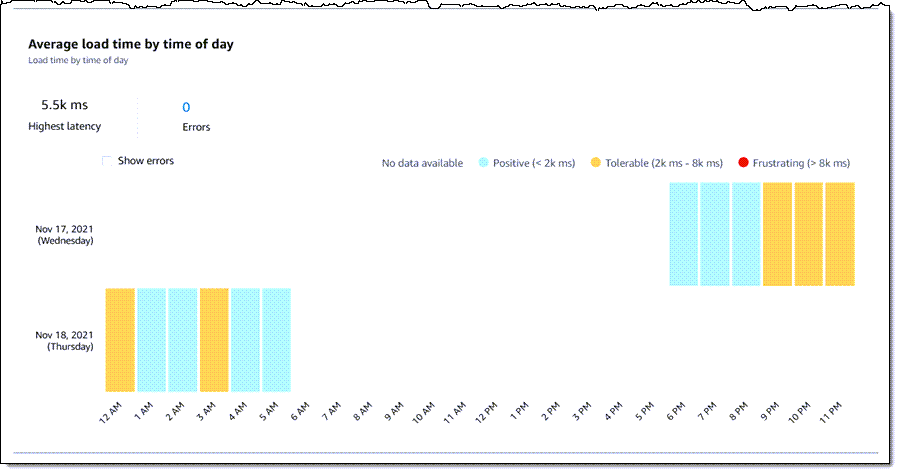
On the observability side, CloudWatch RUM integrates with AWS X-Ray, so you can view traces and segments for end user requests. You can even see your clients in CloudWatch ServiceLens service maps.
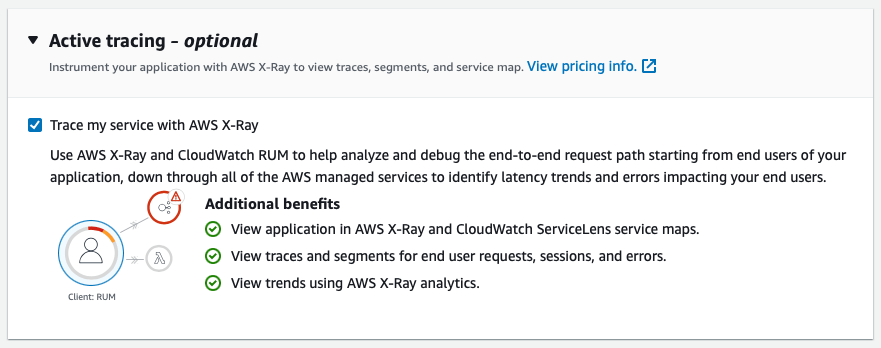
Pricing
As usual with AWS, pricing for these services are based on usage, which means you can try these out on a small scale and then evaluate if the benefits they bring you are worth the cost. Once you use these services in production, always put up some cost monitoring so you remain aware of what you are spending. Below you will find an overview of the pricing for these services. For details, look at their pricing page.
AWS AppConfig Feature Flags are charged by the number of times you request and receive config changes:
- $0.0000002 per configuration request via API Calls
- $0.0008 per configuration received
AWS CloudWatch Evidently has a first time free trial that includes 3 million Evidently events and 10 million Evidently analysis units per account. After that you pay:
- $5 per 1 million events (user actions & assignment events)
- $7.50 per 1 million analysis units
AWS CloudWatch RUM allows you to control costs by configuring it to only analyze a limited percentage of user sessions. There is a first time free trial that includes 1 million RUM events per account. After that you pay:
- $1 for every 100,000 events collected (page view, JavaScript error, HTTP error)
Alternatives
Compared to products that specialize in this field like LaunchDarkly or Optimizely, these AWS services may feel somewhat bare bones. This is no coincidence, as Werner Vogels said: AWS services are designed to be building blocks, not frameworks.
AWS may not be as feature rich as some of these others but having it all integrated into the rest of your service stack can be a big benefit. The low barrier to entry means you can start using it today and get value out of it quickly, or switch to something else later if you discover that your needs have grown.
And don’t forget, if you don’t need all the experimentation statistics or real-time flag controls, just keep it simple and add a few booleans in your code.
Conclusion
It is great to see that AWS is serious about giving their users the keys they need for innovation. What I personally find most exciting is that with this combination of services, AWS makes it easier for all of us to adopt that mindset of doing experiment-based and data-driven roll outs.
If you need help to introduce that mindset of experimentation, don’t hesitate to reach out to us!
To learn more about these AWS services, check out the official blogs:
Meer weten over wat wij doen?
We denken graag met je mee. Stuur ons een bericht.